

Introduction
When speaking with users and customers, we frequently come across north of 100 TB telemetry data generated on a daily basis. This includes all kinds of signals - text heavy logs, high cardinality metrics and wide traces.
Such scale invites questions about the cost of ingestion, storage, query and retention of data.
So, we wanted to dive deeper into the physics and economics behind ingesting 100 TB telemetry data daily, retaining it for 30 days and querying it actively. While economics will help understand the actual cost of software and hardware, Physics allows us to understand the instance types, the network bandwidth, disk I/O required. In this blog, we dive into our test setup, the client and server instances, load generation setup and query setup. Finally, we’ll cover the overall cost incurred on AWS in actuals.
See Parseable Observability Platform in action while we conducted the test run of ingesting 100TB of telemetry data daily.
Background
Parseable is a unified observability system built ground up to handle high volumes of ingestion and fast querying. Parseable is designed to be diskless (i.e. uses object storage as the primary store) and can be scaled horizontally as required. With modern compression techniques, Parseable is able to reduce the overall footprint of ingested data by up to 10x.
You can run Parseable on a cloud provider of your choice or on private cloud infrastructure. In this post, we’ve used AWS EC2 as the deployment platform.
The goals
- Understand the actual cost of infrastructure to run Parseable in a real world scenario.
- Uncover performance constraints or limitations in Parseable's ingestion pipeline, storage mechanisms, and query processing when pushed to extreme workloads.
- Observe Parseable’s behavior during prolonged, heavy usage scenarios, tracking metrics such as ingestion throughput, latency, resource utilization, and overall system stability.
Our setup
- Parseable Cluster: We used AWS CloudFormation to deploy Parseable Enterprise and Node Exporter for metrics collection. We used a total of 7 nodes, with 4 dedicated for ingestion.
- Ingestion Nodes (×4):
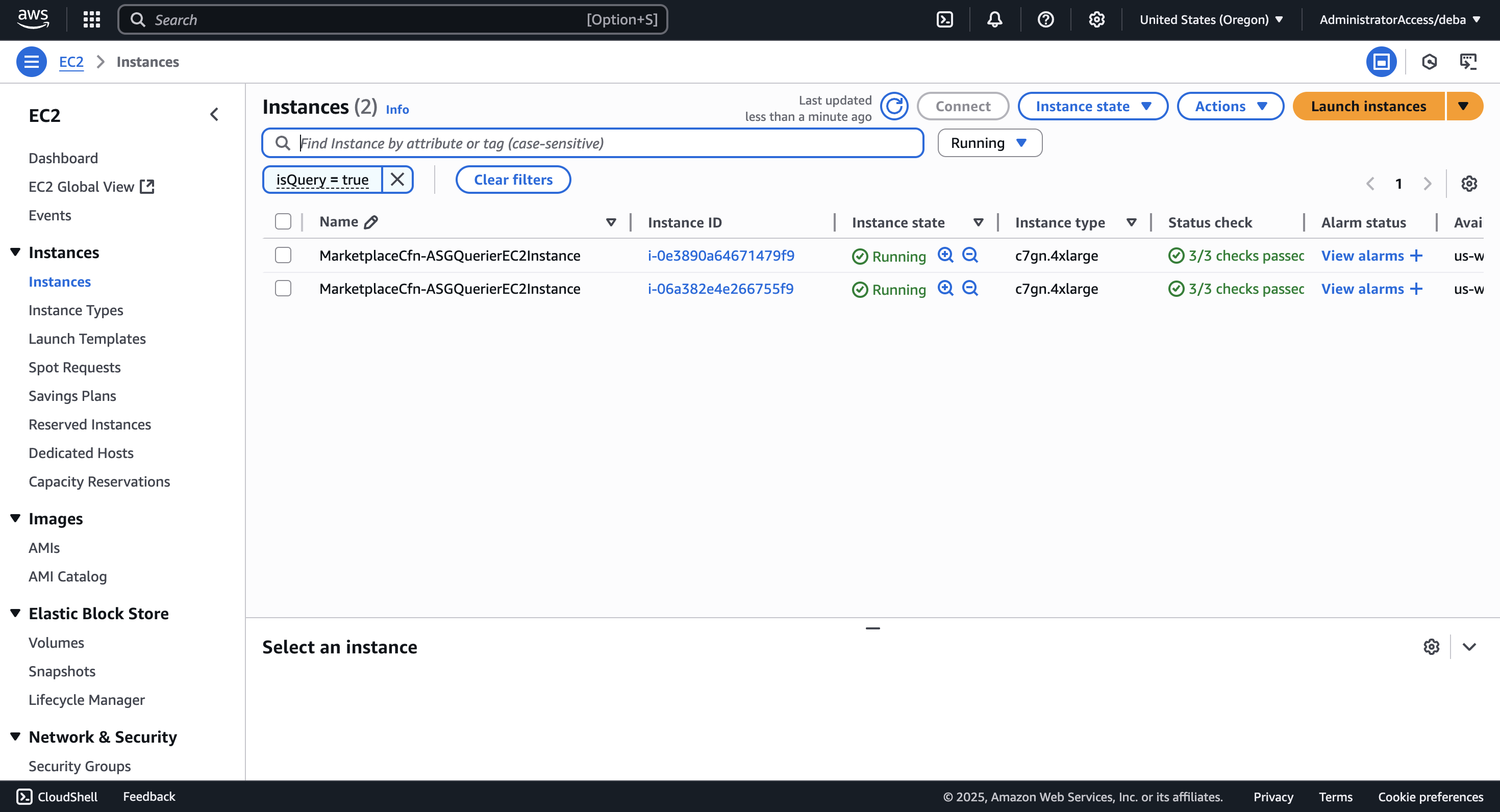
c7gn.4xlarge, 24GB gp3 storage. - Query Nodes (×2):
c7gn.4xlarge, 24GB gp3 storage. - Prism Node (x1):
c7gn.4xlarge, 24GB gp3 storage.
- Ingestion Nodes (×4):
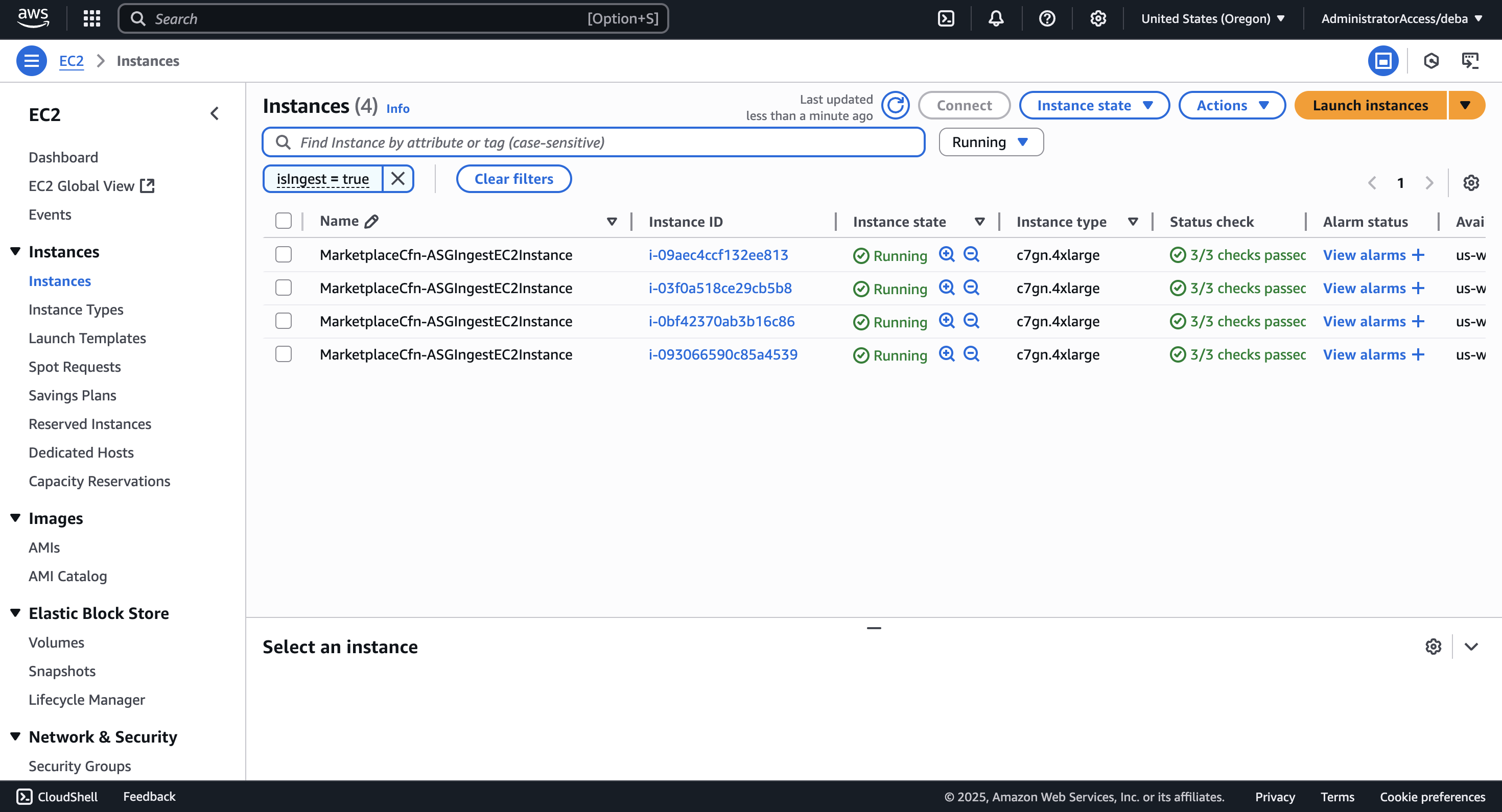
- Using object storage: Parseable’s design leverages object stores (like AWS S3, GCS, Azure Blob), minimizing local disk requirements over longer periods. The disk is primarily used for temporary caching and indexing.
- Disk sizing: For continuous ingestion, make sure each node has enough disk space to handle temporary buffers. A good rule of thumb is to provision at least 2 hours’ worth of peak ingestion as a buffer, split across your ingest nodes.
- Load generation by k6 (by Grafana): for generating sustained high-volume ingestion workloads:
- Installed directly onto EC2-based load-generation nodes, provisioned via CloudFormation. 12 AWS EC2 instances of type
c7gn.4xlargerunning k6. - Staged Virtual Users (VUs): Configured within version-controlled k6 scripts, simulating realistic ramp-up and sustained telemetry ingestion rates.
- Version-controlled k6 scripts ensure consistent, repeatable load scenarios. You can take a look at the k6 script here.
- Installed directly onto EC2-based load-generation nodes, provisioned via CloudFormation. 12 AWS EC2 instances of type
- Monitoring Infrastructure: We also set up a dedicated EC2 instance running Prometheus and Grafana servers to centrally monitor resource utilization and cluster health.
Avoiding the cross AZ data tax
Traditional systems like Elastic are designed to replicate data across multiple Availability Zones (AZs) to ensure data protection and reliability. While this is important for disk based systems, it adds a huge overhead in terms of cost. For example, AWS charges for data transfer between Availability Zones (AZs) within the same AWS region. It is charged at $0.01 per GB in each direction.
So, if you were to ingest 100TB / day in Elasticsearch or OpenSearch, you’ll need to pay USD 10,000 / day just for data ingestion. Note that queries to Elastic / OpenSearch will also need to read data from different shards (cross AZs), which will further add to this cost.
Parseable, because of its diskless design, doesn’t need cross AZ data replication. We recommend running all Parseable nodes within the same AZ as the application generating data. Even if the application is running across multiple AZs, you can have Parseable nodes (from the same cluster) running in different AZs. Since all Parseable nodes connect to the S3 bucket only, there is no cross AZ data transfer.
To summarise, we set up 4
c7gn.4xlargenodes for ingestion (Parseable) and 12c7gn.4xlargeload generation servers (k6) for this experiment. Each Parseable ingestion node had 3x load generators.
Test run
Once the setup was done to our satisfaction, we ran the ingestion load generation for exactly 1 hour to understand the ingestion performance at sustained high load. Here are the results:
Ingestion Performance
- Total Ingested Data: 2TB over 4 nodes, i.e. 500GB/node/hour. The ingestion rate was consistent across nodes.
- Minimal Disk Usage: Baseline 24GB storage demonstrated efficient disk management via rapid offloading to S3.
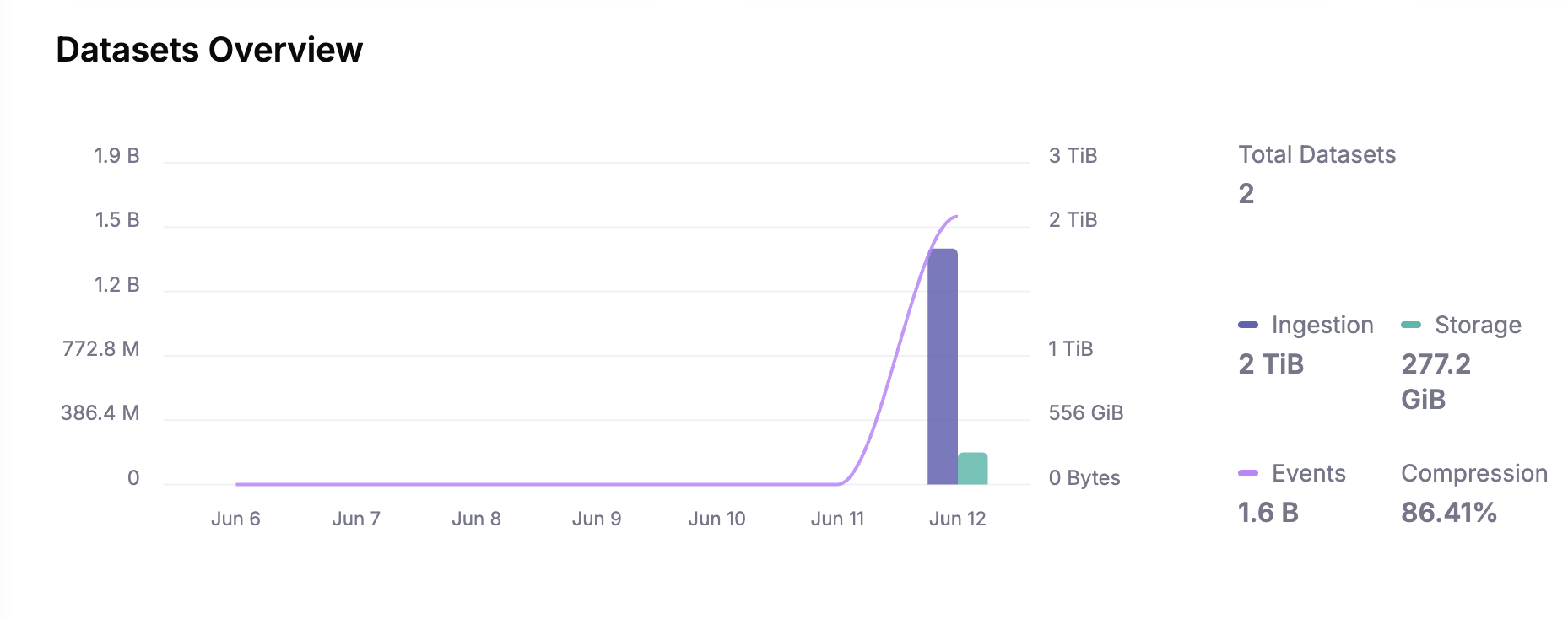
Even at extreme ingestion rates, Parseable’s queries remained in milliseconds, showcasing efficiency even at this scale.
Query Performance
- Typical queries continued executing in the milliseconds range.
- This demonstrates Parseable’s efficient internal indexing, leveraging columnar storage formats and optimized Rust-based query engine.
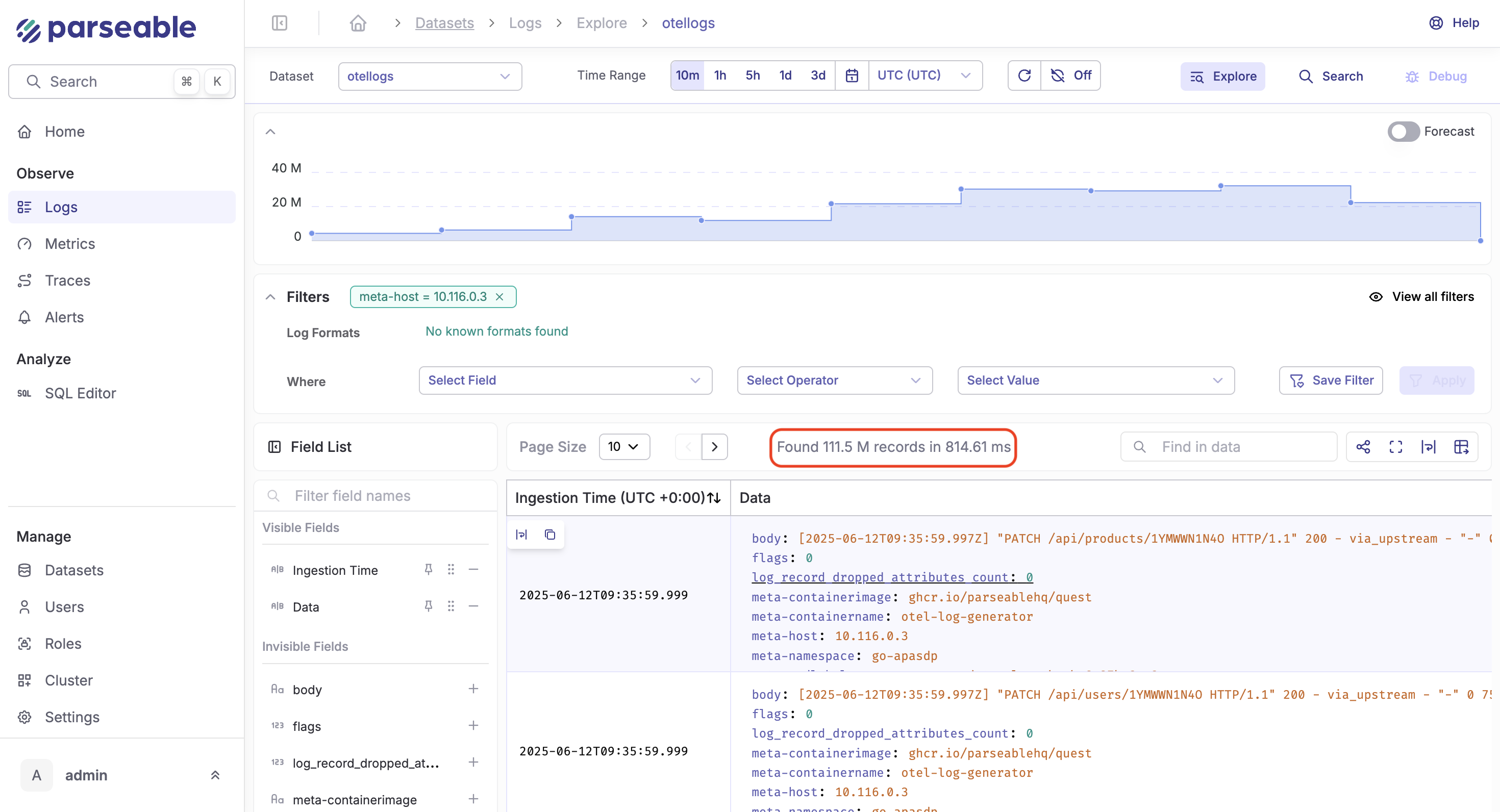
Extrapolation & cost analysis
Based on the above observations, let’s extrapolate the numbers to see how we can reach 100 TB and beyond.
- With 4 ingest nodes, current throughput was 2TB/hour, this means 0.5TB/hour/node.
- To reach the target daily throughput: 100TB/day ≈ 4TB/hour.
- Required nodes: 4TB/hour ÷ 0.5TB/hour/node ≈ 8 nodes
Proposed Infrastructure for 100TB/day
- Prism Node: 1 ×
c7gn.4xlarge - Ingestion Nodes: 8 ×
c7gn.4xlarge, base disk size with no additional mounts. - Querier Nodes: 2 ×
c7gn.4xlarge(extra redundancy for queries at scale)
Approximate costs for 100TB/day scenario
| Resource | Instances | Cost per instance/hr | Daily cost (24 hrs) | Monthly cost (30 days) |
|---|---|---|---|---|
| EC2 Ingestors | 8 | ~$0.62 (1 Yr Reserved) | $119.04 | ~$3571.20 |
| EC2 Queriers | 2 | ~$0.62 (1 Yr Reserved) | $29.76 | ~$892.8 |
| EC2 Prism Node | 1 | ~$0.62 (1 Yr Reserved) | $14.88 | ~$446.40 |
| EC2 Total | 11 | ~$0.62 (1 Yr Reserved) | $261.36 | ~$4910.40 |
| S3 Storage | 3 PB/month ingested, compressed to 300 TB/month stored. Compression ratio ~10:1. | 300,000 GB × $0.023/GB/month | ~$6900 | |
| Monthly Total | ~$11,810.40 |
(Note: Costs will vary based on data lifecycle policies and AWS pricing specifics. Also this excludes the S3 data transfer charges that vary on number of calls / queries run.)
Observations
Data sovereignty and a balance of cost vs RoI is one of the key requirements today for Enterprise users. Additionally fragmentation of data across different tools is a major concern - this fragmentation is a hindrance to MTTR. Finally there is a lot of expectation in the ecosystem to leverage AI to reduce cognitive loads.
With Parseable, we're looking to solve these challenges with a modern, cloud native approach and focus on ease of use and performance.
In this experiment, we observed that the S3 first architecture scales linearly with new ingestion nodes as needed. Additionally, the query performance holds up very well using the efficient disk caching mechanism that intelligently moves data between S3 bucket and the local disk as needed.
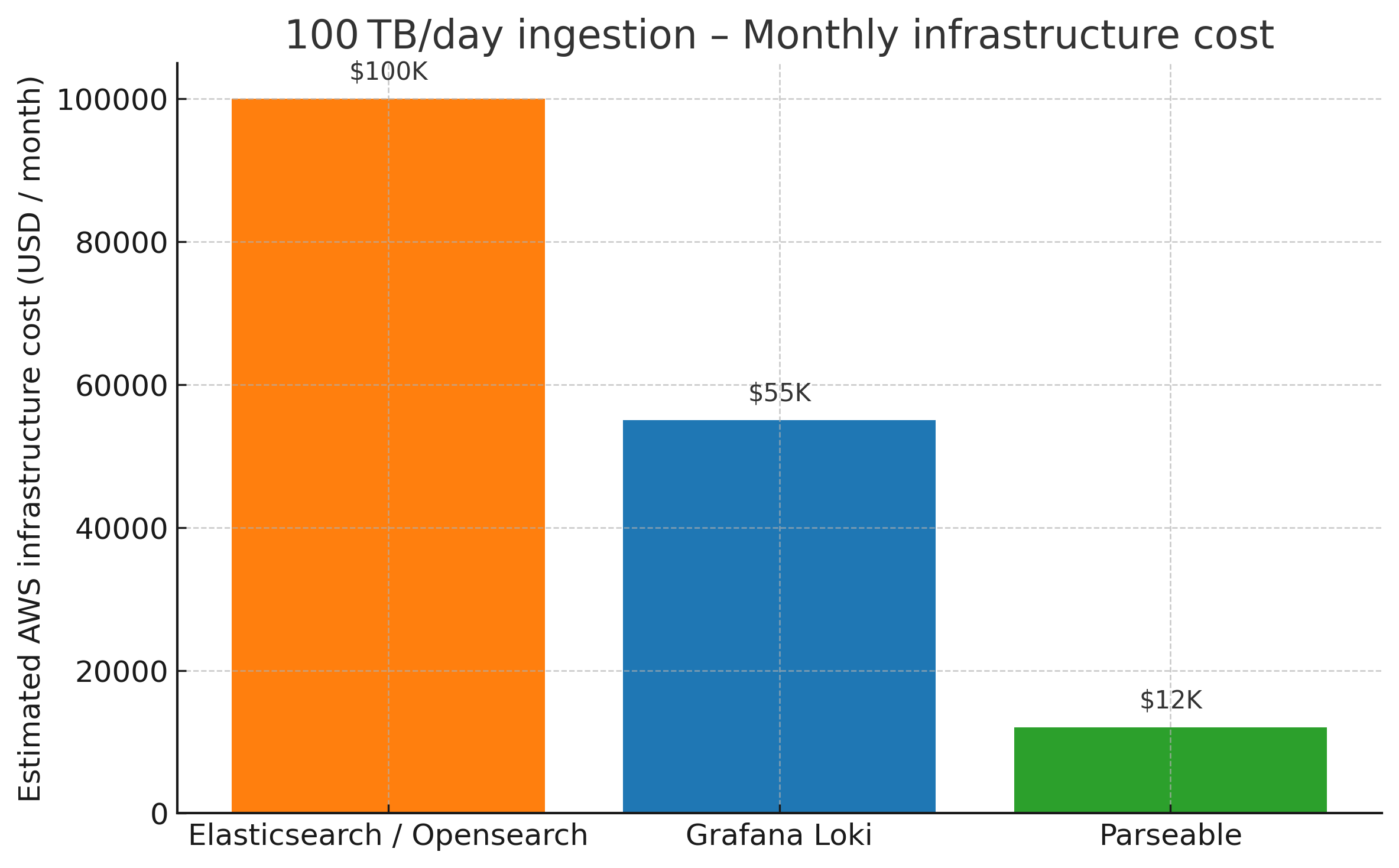
All this was possible at a fraction of the infrastructure cost when compared to Elasticsearch and Grafana Loki. Based on rough estimates, the AWS infrastructure cost for Elasticsearch / Opensearch at this volume would be roughly USD 100K, the AWS infrastructure cost for Grafana Loki would be roughly USD 55K, while Parseable's infrastructure cost is at USD 12K.
Closing notes
Through this testing, Parseable proved its capacity to scale smoothly to 100TB/day ingestion workloads without sacrificing query performance. Our streamlined architecture built on efficient Rust implementation, object storage scalability, and optimized indexing makes Parseable suitable for extremely high-volume observability scenarios.
Interested in replicating this test or scaling Parseable in your own environment? Feel free to reach out or join our Slack community to discuss your use case.

