

Introduction
On October 20, 2025, when AWS us-east-1 had its DNS wobble, the internet felt it; apps we use every day staggered because a single region had a bad day. That’s the quiet truth of cloud design: a region is a failure domain.
When an observability stack writes to an object-store in a particular region, your ingest and queries inherit that blast radius, any downtime in that region affects your observability pipeline. Parseable is an observability platform built to make sense of large volumes of telemetry data (logs, metrics, and traces). It uses columnar storage format with an object storage first approach.
Columnar storage organizes data by columns rather than rows. For analytical queries that often only require a subset of columns, this means significantly less data needs to be read from object store, directly translating to lower data transfer costs and faster query execution, but that advantage holds only if the store is consistently available.
Tigris didn’t go down in the outage. By being a globally distributed S3-compatible object store that places data near writers, caches it near readers, and lets you span buckets across multiple regions, it’s highly available. If a region goes down, writes are sent to the next nearest region, reads keep flowing from a healthy endpoint, and your observability stack stays intact. Together, Parseable + Tigris turn “single-region fragility” into “multi-region resilience,” keeping your telemetry online, your p95s sane, and your team focused on meaningful work instead of outages.
In this blog, we’ll go through how to configure Parseable for observability along with Tigris as the S3-compatible, multi-region object store.
Configure Parseable with Tigris
- Create a Tigris account, bucket & access key
- Refer to the Tigris docs to create your account, bucket, and an access key / secret.
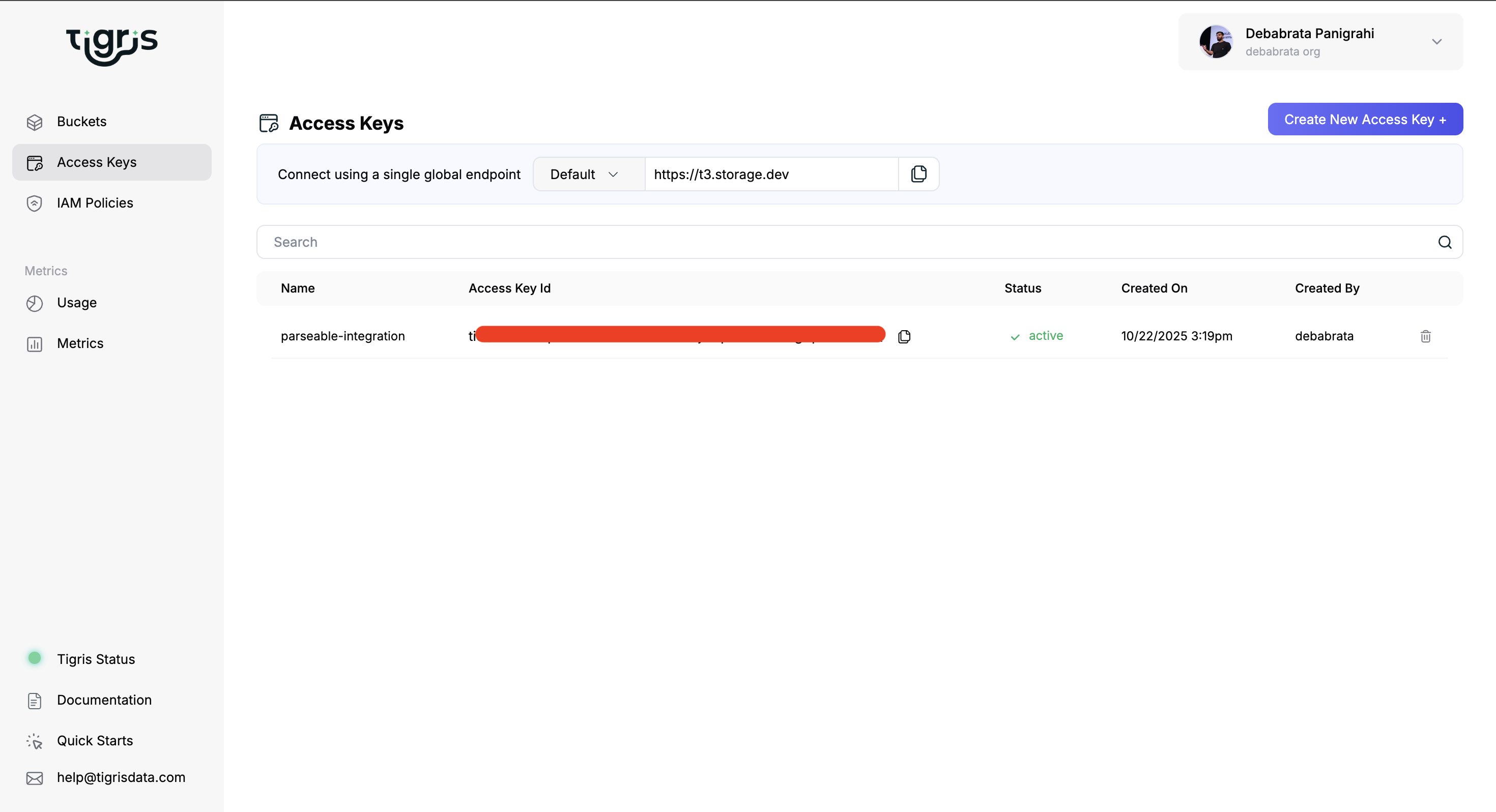
You’ll need these for Parseable:
-
P_S3_URL -
P_S3_BUCKET -
P_S3_ACCESS_KEY -
P_S3_SECRET_KEY -
P_S3_REGION -
Set up environment variables for Parseable
-
Based on the information collected above, create a file named
parseable-envand add:
P_STAGING_DIR=/staging
P_ADDR=0.0.0.0:8000
P_USERNAME=admin
P_PASSWORD=admin
P_S3_URL=https://t3.storage.dev
P_S3_BUCKET=demo-parseable
P_S3_ACCESS_KEY=tid_bBriOhfcBFdcPalcgApTNQtMCQ
P_S3_SECRET_KEY=tsec_PYgPCg1lqgsJYe+NeAZfuCgeCONc30ovny
P_S3_REGION=autoInstall Parseable
Parseable is available in two variants: Distributed and Standalone, covering everything from small-scale testing to large-scale production.
Make sure to start Parseable in S3 mode when using the Standalone image.
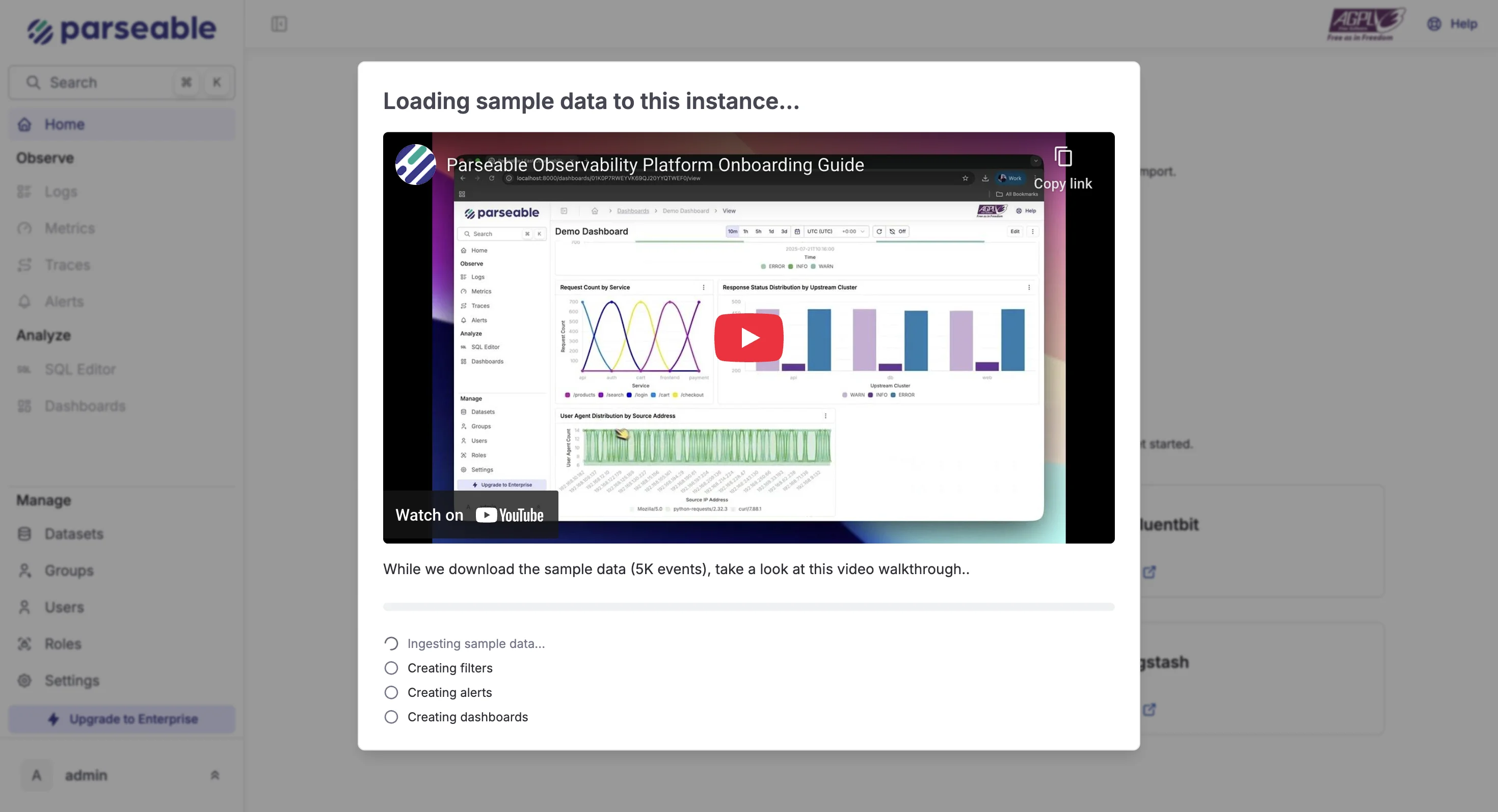
Sample data
Once Parseable is installed, access the UI at http://localhost:8000/. Load the sample data, then open the Tigris Console to verify that objects are created in your bucket.
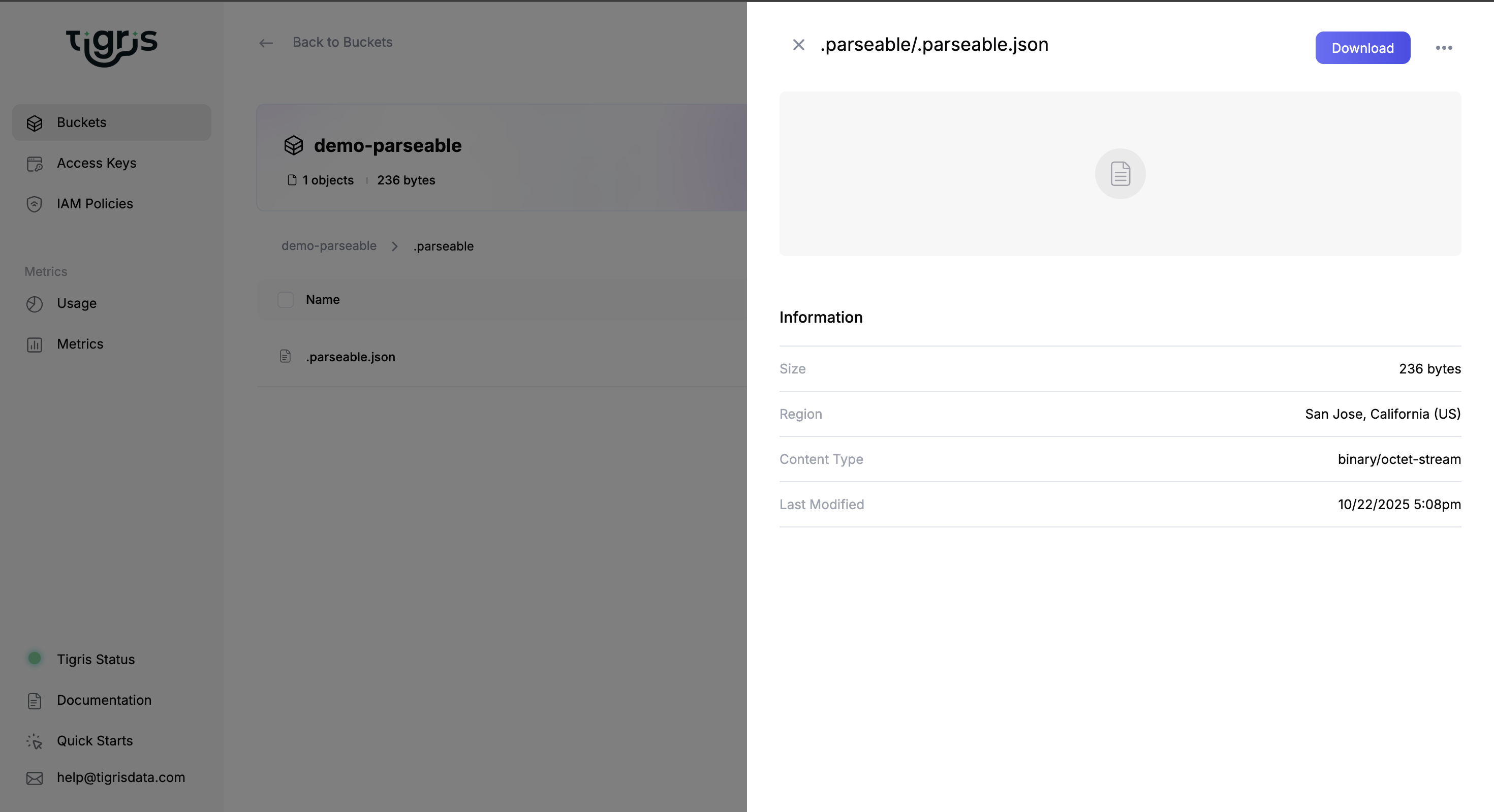
That’s it, you’ve got Parseable writing telemetry to a multi-region, S3-compatible Tigris bucket.
Conclusion
A compressed columnar store on an object-first architecture is the practical answer to storing petabytes of observability data without compromising production-grade resilience: columnar storage format + compression delivers smaller footprints and faster scans, reading fewer bytes to answer more queries. An object-store-first design unlocks scale and simplifies retention. You can keep months of history without running hot replicas. And with Tigris as a distributed, S3-compatible object store, you gain multi-region resilience and cost-efficient durability without burning cash on egress fees across clouds and regions.
Parseable’s faster query engine is further complemented by Tigris’s fast retrieval for small objects, makes frequent, focused reads efficient, ideal for real-time troubleshooting and alert investigations.
Parseable + Tigris gives you resilience without runaway cost, retention without trade-offs, and fast queries at scale, a highly viable, modern foundation for observability.
Try Tigris's new bucket forking feature, create instant snapshots and zero-copy forks of your observability data for testing, dev environments, or compliance without duplicating storage. Learn more

